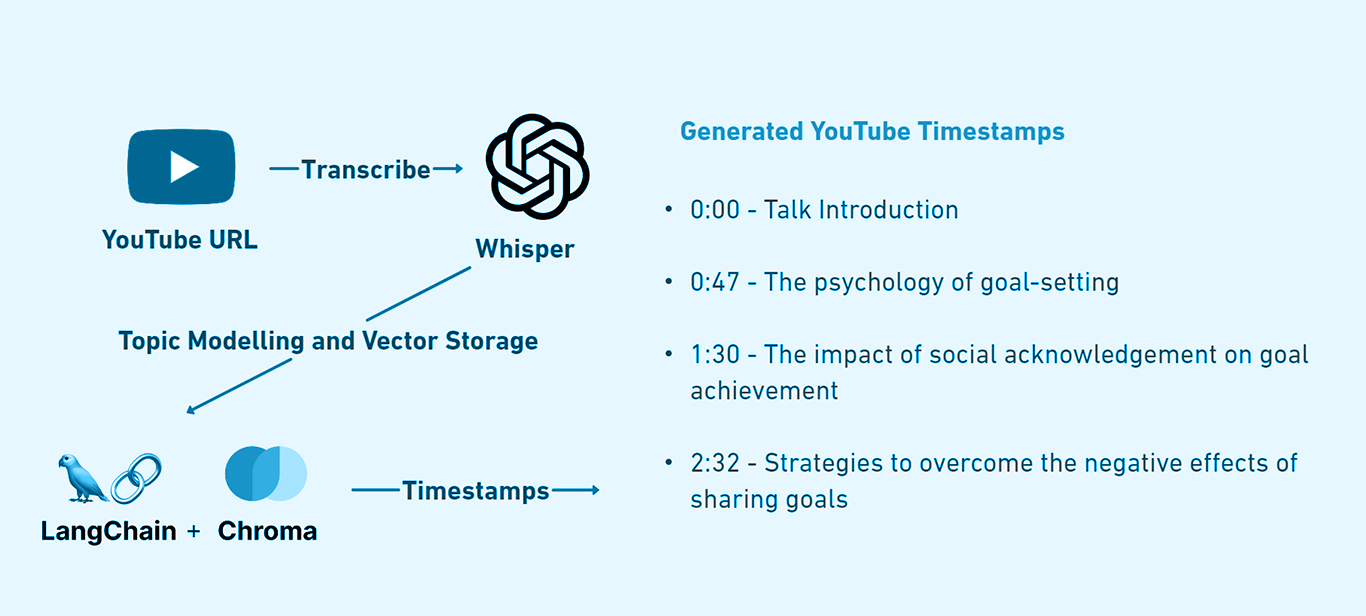
URL to Video Timestamps
Goal
This is a simple walkthrough showcasing how to use LangChain, Whisper, and other tools to create a useful project in a few lines of code. There already exists paid tools to do this, like PocastNotes, but I wanted to recreate it for the sake of learning.
Problem
It takes content creators a lot of time to create timestamps for their videos, especially long form ones like podcasts. This is a tedious process that can be automated.
Extra ideas
You can take this project further using these ideas:
- Create a streamlit interface for this project
- Create a chrome extension that adds timestamps to youtube videos
- Connect it to youtube api to automatically add timestamps to videos
- Use it to create a podcast search engine
- Generate table of contents for blogs
Process
- Convert youtube video to audio file
- Transcribe audio file to text using Whisper, and Whisper-Timestamped
- Use LangChain to split the text and extract main ideas (title and brief description)
- Store the text into chunks in a vector database, I used ChromaDB
- Iterate through the ideas and find the most similar chunks in the database, then extract the timestamp
1. Convert youtube video to audio file
This step is really simple all you have to do is use yt-dlp to get an audio file from a youtube link
import yt_dlp
url=r"https://www.youtube.com/watch?v=NHopJHSlVo4"
video_info = yt_dlp.YoutubeDL().extract_info(url = url,download=False)
options={
'format':'bestaudio/best',
'keepvideo':False,
'outtmpl':'audio.mp3',
}
with yt_dlp.YoutubeDL(options) as ydl:
ydl.download([video_info['webpage_url']])
2. Transcribe audio file to text
For this step we will use Whisper-Timestamped whisper-timestamped is an extension of openai-whisper python package
import whisper_timestamped as whisper
audio = whisper.load_audio("audio.mp3")
model = whisper.load_model("tiny")
result = whisper.transcribe(model, audio, language="en")
result is a json object containing the transcribed text and timestamps, we don’t need everything so we will format it into “timesamp - text” the code for this is available in the notebook. e.g: 0:00:27: Imagine deciding right now that you’re going to do it.
3. Use LangChain to split the text and extract main ideas
I used gpt-3.5-turbo-0613 from OpenAI, you can use any LLM you want. If you are gonna use an LLM from OpenAI, you can get an api key from here We are gonna split the text into chunks, this was we can handle long texts like podcasts then apply langchain’s map reduce to extract the main ideas. You can read more about map reduce here where we define two prompts one for mapping and one for combining the results.
llm=ChatOpenAI(model="gpt-3.5-turbo-0613",openai_api_key=OPENAI_API_TOKEN)
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", " "],chunk_size=10000, chunk_overlap=2200)
docs = text_splitter.create_documents([transcript])
print (f"You have {len(docs)} docs.)
I did’t include the code for the map reduce because it’s a bit long, but you can find it in the notebook. We get a result like this
{
"topics": [
{
"title": "The psychology of goal-setting",
"description": "Telling someone your goal makes it less likely to happen because it tricks the mind into feeling that it's already done."
},
{
"title": "The importance of delaying gratification",
"description": "Resisting the temptation to announce your goal and delaying the gratification that social acknowledgement brings can help you stay motivated and focused on achieving your goal."
}
// and so on
]
}
4. Store the text into chunks in a vector database
I used ChromaDB for this step, you can use any vector database you want. You also need an embeddings model, I used OpenAI’s.
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_TOKEN)
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(docs, embeddings)
5. Iterate through the ideas, find the most similar chunks in the database, then extract the timestamp
We’ll do this using a prompt + RetrievalQA chain from langchain. Here’s the prompt
system_template = """
What is the first timestamp when the speakers started talking about a topic the user gives?
Only respond with the timestamp, nothing else. Example: 0:18:24
----------------
{context}"""
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template("{question}"),
]
CHAT_PROMPT = ChatPromptTemplate.from_messages(messages)
Getting the timestamps
qa = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(k=4),
chain_type_kwargs = {
'prompt': CHAT_PROMPT
})
# Holder for our topic timestamps
topic_timestamps = []
for topic in topics_json['topics']:
query = f"{topic['title']} - {topic['description']}"
timestamp = qa.run(query)
topic_timestamps.append(f"{timestamp} - {topic['title']}")
Result:
0:00:47 - The psychology of goal-setting
0:01:30 - The impact of social acknowledgement on goal achievement
0:02:32 - Strategies to overcome the negative effects of sharing goals